NLAFET mission
Today’s largest HPC systems have a serious gap between the peak capabilities of the hardware and the performance realized by high-performance computing applications. NLAFET is a direct response to this challenge. NLAFET will enable a radical improvement in the performance and scalability of a wide range of real-world applications, by developing novel architecture-aware algorithms, and the supporting runtime capabilities to achieve scalable performance and resilience on heterogeneous architectures. The validation and dissemination of results will be done by integrating new software solutions into challenging scientific applications in materials science, power systems, study of energy solutions, and data analysis in astrophysics. The software will be packaged into open-source library modules.NLAFET sample results
The main scientific and technological achievements include advances in the development of Parallel Numerical Linear Algebra algorithms for dense and sparse linear systems and eigenvalue problems, the development of communication avoiding algorithms, an initial assessment of application use cases, and an evaluation of different runtime systems and auto-tuning infrastructures. The novel software developed and deployed are available via the NLAFET website www.nlafet.eu/software and associated 13 public GitHub repositories structured in five groups: Dense matrix factorizations and solvers; Solvers and tool for standard and generalized eigenvalue problems; Sparse direct factorizations and solvers; Communication optimal algorithms for iterative methods; Cross-cutting tools. The parallel programming models used include MPI, OpenMP, PaRSEC and StarPU. NLAFET software implementations are tested and evaluated on small- to large-scale problems executing on homogeneous systems and some on heterogeneous systems with accelerator hardware. Scientific progress and results of NLAFET have been presented at several international conferences and in scientific journals (see www.nlafet.eu/publications ).NLAFET impact
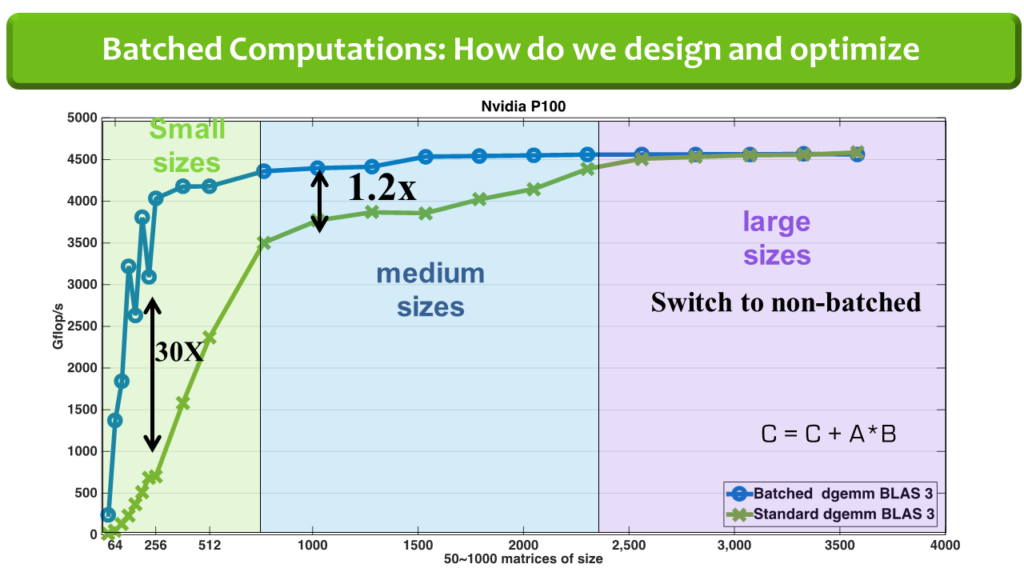
The main impact is the software available, via GitHub NLAFET repositories, to the scientific community and industry, and thereby providing novel tools for their computational challenges. The work on the batched BLAS specification has already achieved considerable impact with industry in reaching a community standard. The idea is to group multiple independent BLAS operations on small matrices as a single routine (see the figure). The graph shows performance on an Nvidia P100 GPU for 50 to 1000 GEMM operations on matrices of size 16-by-16 up to 4000-by-4000. For example, for matrices of size 256-by-256 around 30 times speedup is obtained compared to CuBLAS GEMM. For large matrix sizes we switch to non-batched BLAS. Sample applications for batched BLAS can be found in Structural mechanics, Astrophysics, Direct sparse solvers, High-order FEM simulations, and Machine learning.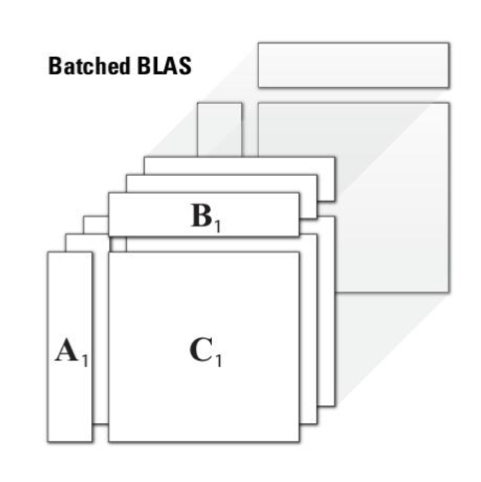
Previous image
Next image